
Data Handling and Privacy
Smart Talk Insights is an AI-enhanced conversation intelligence platform that:
- Captures business conversations from multiple channels
- Transcribes and structures the data
- Applies AI analysis to generate insights
- Enables natural language querying
- Links all insights back to source evidence
Click image to englarge.
What does Smart Talk Insights (STI) analyse – call recording or transcripts?
Smart Talk Insights processes the recordings and then analyses the transcripts:
1. Initial audio/video processing
- Audio and video recordings are captured first
- These are processed through automated speech-to-text transcription
- Speaker identification and diarisation occurs at this stage
2. AI analysis operates on text
The downstream AI analysis works on the text/transcript layer:
- Summarisation
- Pattern recognition
- Process fulfillment tracking
- Sentiment-style outputs
- Topic extraction
3. Key distinction
Smart Talk Insights is not an emotion-recognition system that infers emotions from voice biometrics. The analysis focuses on:
- What was said (content/text)
- Not how it was said (voice characteristics/biometrics)
If a customer specifically wanted to infer emotions from acoustic/biometric data (analysing tone, pitch, stress patterns), that would:
- Require a separate legal assessment
- Need a dedicated high-risk conformity package under the AI Act
- Generally be prohibited in workplace settings except for medical/safety purposes
So while Smart Talk Insights processes the audio to create transcripts, the AI insights and analysis are derived from the textual content, not from analysing voice characteristics or biometric data.
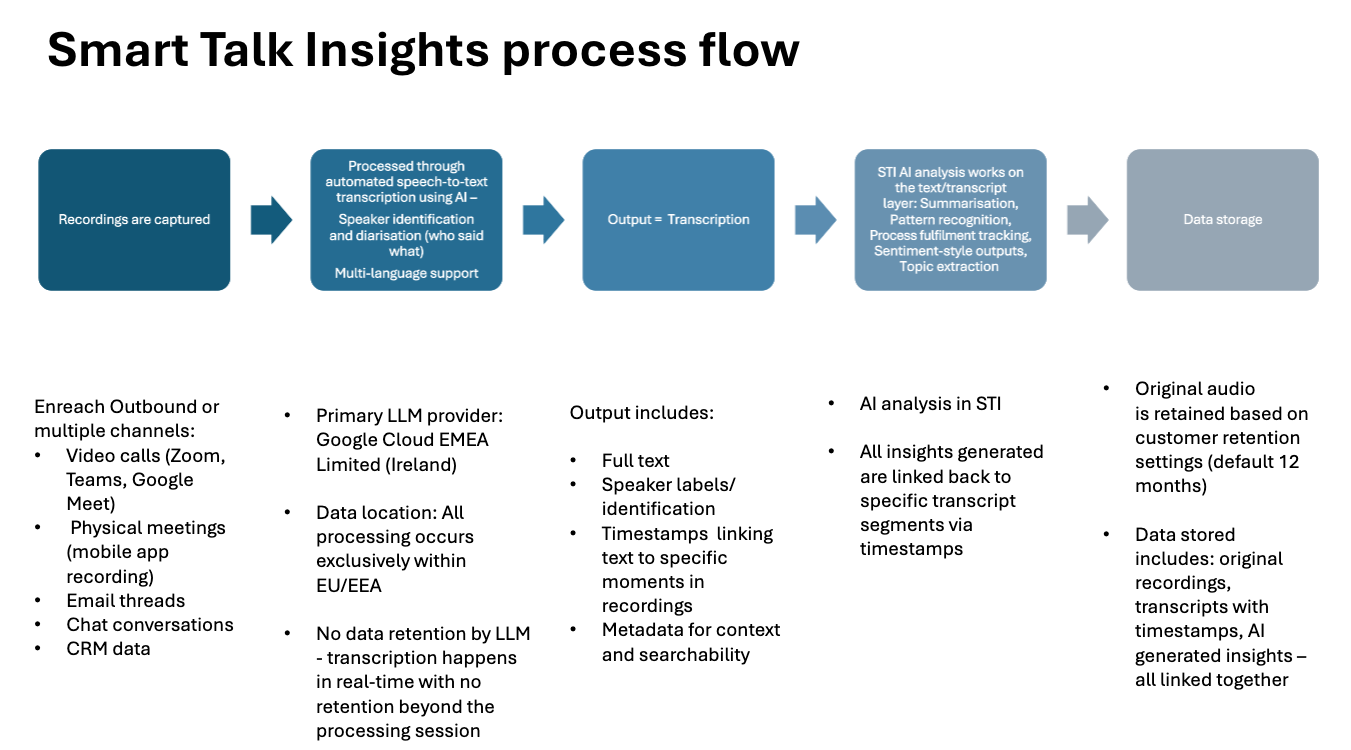
Here is the transcription process flow for Smart Talk Insights:
1. Data capture
- Audio/video from multiple sources: video calls, phone calls, physical meetings, etc are captured
- All recording happens within EU/EEA infrastructure
2. Speech-to-Text conversion
The system performs:
- Automated speech-to-text transcription using AI
- Multi-language support (specific languages not detailed in documentation)
- Speaker identification and diarisation - distinguishing who said what
- Processing happens in real-time or near-real-time
3. Technical infrastructure
- Primary LLM provider: Google Cloud EMEA Limited (Ireland)
- Data location: All processing occurs exclusively within EU/EEA
- No data retention by LLM: Transcription happens in real-time with no retention beyond the processing session
4. Output format
Transcripts include:
- Full text of what was said
- Speaker labels/identification
- Timestamps linking text to specific moments in recordings
- Metadata for context and searchability
5. Post-transcription
Once transcribed:
- Text becomes the primary layer for all AI analysis
- Original audio is retained based on customer retention settings (default 12 months)
- All insights generated are linked back to specific transcript segments via timestamps
- Pre-anonymisation would lead to three critical failures:
1. Lack of business intelligence
- No individual tracking = No agent coaching or performance management functionality
- No CRM connection = Every conversation floats in isolation
- No relationship mapping = Lost customer journey
- Result: Collection of random conversations, not organisational memory
2. Unable to use AI to ask specific questions about the data
- You can't ask about specific people or companies
- Generic questions yield generic answers
- Loses ability to connect dots across conversations
- Result: Expensive transcription service, not intelligence platform
3. Technical reality:
- Same person labelled differently across calls
- Context stripped away making insights meaningless
- Privacy theatre - speech patterns still identify people
- Result: Inconsistent data that's neither useful nor truly anonymous
Rather than pre-anonymisation, it may be possible to explore:
- Enhanced access controls
- Automated PII detection and masking for specific fields
- Shorter retention for sensitive data
- Stronger audit trails
This preserves the platform's intelligence while addressing privacy concerns.
We are currently discussing how this could work for customers with Meetric.
What are STI’s current anonymisation capabilities?
STI only anonymises data, post-LLM processing, for its own AI training, performance analysis, and product improvement. This is an irreversible anonymisation process and follows DPIA-assessed methodology. Customers are able to opt out of the ‘system training’ by requesting an exemption.
How can B2C organisations utilise STI, given strict data privacy regulations in Denmark and Sweden?
Privacy-first implementation:
- All data stays within EU/EEA
- Swedish/Danish data protection laws fully supported
- No emotion/biometric analysis (avoiding AI Act restrictions) – text-based analysis
- Clear retention controls (adjustable from 12 months)
- Audit trails for compliance documentation
Consumer consent approach:
- Provide clear notification for customers at the start of the call
- Explain the purpose limitation (quality/sales agent training/improvement)
- Explain retention period disclosure
- Support a customer’s right to erase
Can we control who sees what data?
Absolutely - this is core to STI’s design. You have multiple layers of control:
- Department-based logic - Sales can't see HR conversations, support can't see sales calls
- Role-based permissions - Control access by seniority, team, or function
- User-level controls - Individual access can be customized
- Audit trails - See exactly who accessed what and when
Common B2C privacy objections & responses:
1. "We can't record customer calls without explicit consent"
Response:
STI fully supports consent-based workflows:
- Clear notification at call start
- Purpose specification (quality, sales agent training, improvement)
- Retention period disclosure
- Documented consent management
Key point: STI provides the infrastructure - you control the consent process. Many B2C organisations already record calls - STI makes that data actionable while maintaining compliance.
2. "Customer data is too sensitive for AI processing"
Response:
STI privacy-first approach:
- EU-only processing - No data leaves EU/EEA
- No emotion/biometric analysis - Text-based insights only
- No AI LLM training on your data - Contractually guaranteed with our LLM providers
- Configurable retention - As short as needed (even 30 days)
- Instant deletion - Honor customer requests immediately
- Granular access controls - Only authorized people see sensitive conversations (see above)
Reframe: "Your customer data is already in call recordings. STI adds intelligence while actually improving privacy through better governance and automated retention management."
3. "GDPR fines are too risky"
Response:
STI helps reduce GDPR risk:
- Built-in compliance features - Audit trails, retention controls, access logs
- Proven DPA - Comprehensive data processor agreement
- Privacy by design - Not privacy as afterthought
- Supervisory authority alignment - Designed for EU compliance
Evidence: Used by regulated industries including recruitment (Teamtailor), financial services, and healthcare adjacents.
4. "Customers will object if they know AI analyses their calls"
Response:
Position it as customer benefit:
- Better service - Faster issue resolution
- Quality assurance - Consistent experiences
- No human listening - AI respects privacy more than human reviewers
- Pattern detection - Spot systemic issues faster
Messaging: "We use secure EU-based AI to ensure every customer gets our best service, identify common issues quickly, and train our team more effectively."
5. "We can't have customer data in the cloud"
Response:
STI's enterprise-grade security:
- ISO 27001 pathway - External audit April 2026
- EU data centres only - Sweden, France, Netherlands
- Encryption everywhere - Transit and rest
- Zero trust architecture - Multiple security layers
Reality check: "Your current call recordings are likely already cloud-stored. STI adds intelligence while improving security governance."
6. "What if there's a data breach?"
Response:
Comprehensive breach readiness:
- 24-hour notification - Faster than GDPR requires
- Incident response plan - Tested and documented
- Breach assistance - Full support included
- Security measures - Minimise breach risk
Context: Text transcripts are less sensitive than payment data or passwords you already protect.
7. "Our legal team will never approve this"
Response:
Built for legal approval:
- Standard DPA available - Pre-reviewed by many legal teams
- Clear documentation - All policies publicly available
- Swedish company - Strong privacy tradition
- Reference customers - Other strict-compliance companies use it
Approach: "Let's start with a pilot on non-sensitive customer service calls to demonstrate value and compliance."
8. "Competitors might learn our customer insights"
Response:
Complete data isolation:
- No AI LLM training on your data - Contractually guaranteed
- Dedicated workspace - Your data never mixes
- Role-based access - You control who sees what
- No shared learning - Your insights stay yours
Are system logs available?
Audit-ready logs and audit trails are built-in platform features. STI maintains records of all categories of processing activities carried out on behalf of the customer.
Regarding AI/prompt-related logs specifically: active chat conversations displayed in the platform UI are retained as part of the product experience and can be archived or deleted by the user. Separate internal operational logs for debugging, troubleshooting, and service analysis are retained for 30 days and then deleted.
Types of logs available:
1. Audit logs & trails
- Built-in platform feature for compliance and security
- Tracks user activities, access, and system events
- Part of Smart Talk Insight's GDPR-ready infrastructure
2. Processing activity records
Smart Talk Insight maintains records of all categories of processing activities on behalf of the Customer, including:
- What data was processed
- When processing occurred
- Processing purposes
- Data categories involved
3. User-facing logs
- Users can access their query history
- Retained until archived or deleted by the user
4. Internal operational logs
- Used for debugging and troubleshooting
- Include technical system logs and service analysis data
- Retention: 30 days, then automatically deleted
How is backup implemented? What is the retention period for backups?
STI maintains production database backup and recovery controls for the data it processes.
Backup implementation:
1. Automated daily backups
- Production database backups performed automatically every day
- No manual intervention required
- Covers all customer data processed in the Services
2. Retention & recovery
- 30 backup cycles retained (approximately 30 days of daily backups)
- 7 days of point-in-time recovery capability
- After 30 cycles, older backups are overwritten in normal rotation
3. Storage location
- All backup data stored within the EU with the same data residency guarantees as production data. No backups are transferred outside EU/EEA.
4. Deletion timing:
- Deleting data from production does not immediately delete it from backups
- Backup copies remain until the 30-day retention period expires
- Then automatically purged in normal backup lifecycle
5. Backup scope
Includes:
- Customer conversation data
- Transcripts and recordings
- Analysis results
- Configuration and settings
When data deletion is requested, STI’s secure deletion procedures cover both production and backup systems, with written certification provided upon request.
How is data deletion handled? How is the retention period for transcripts and analysis managed, and for how long?
Data deletion framework for conversations, transcripts, and analysis:
1. During active agreement - retention controls
The default data retention period is 12 months. Customers can adjust the retention settings in the platform’s UI. When the retention period expires data is automatically removed from active access and purged.
2. Upon contract termination
Upon contract termination, access to the platform ceases immediately and all customer data is deleted within 30 days (exception: If otherwise agreed in writing or required by law).
3. Deletion scope and process
Deletion covers production systems, backup systems, archives and disaster recovery backups.
4. LLM/AI processing
Third-party LLMs retain no data beyond the immediate processing session. This is real-time/near-real-time processing only and they are contractually forbidden from using customer data to improve or teach their AI models.
5. Data export option
Before deletion, customers can request assistance (may be compensated) with data exporting, which can include audio, transcripts, metadata.
What specific data is stored – raw data or the analysis results? Are they stored separately?
Both raw data and analysis results are stored in STI, and they're interconnected rather than separated.
What's stored:
1. Raw source material including original recordings (audio/video), complete transcripts, email threads, chat conversations, all metadata (timestamps, speakers, etc.)
2. Analysis results including AI-generated summaries, insights and patterns detected, topic extractions, sentiment indicators, process compliance scores, all derived intelligence.
How they're connected:
These are not stored separately, they are linked together. Every insight is directly linked to source material through precise timestamps so users can always "drill down" from an insight to the exact conversation moment. This traceability is core to Smart Talk Insights’ value proposition. This design ensures insights are always evidence-based and traceable, not standalone conclusions.
Both raw data and analysis results follow the same retention period (default 12 months) and when retention expires, both are deleted together. Customer can configure retention in platform settings.
Is metadata used in the analysis?
Metadata is used by STI and includes:
- Speaker identification - who said what
- Timestamps - precise timing of statements
- Speaker diarisation - separating different speakers
- Device identifiers
- IP addresses
- Account/user IDs
- Session identifiers
- Connection data
- Operational metadata
Metadata enables accurate speaker attribution, contextual analysis, cross-conversation patterns and integration with business systems.
In which country is the data processed and stored, and is it transferred outside the EU?
All personal data, including data processed by third-party Large Language Models (LLMs), is handled, processed and stored exclusively within EU/EEA infrastructure. Specific countries include: Sweden, France, Belgium, Netherlands, Finland
Sub-processors (All EU/EEA):
- Entire Nordic AB - Uppsala, Sweden
- Scaleway - Paris, France
- Google Cloud EMEA Limited - Ireland (using EU data centers only)
Processes
Data flow process:
CAPTURE
Multiple sources → Platform
• Video calls (Zoom, Teams, Google Meet)
• Phone calls
• Physical meetings (mobile app recording)
• Email threads
• Chat conversations
• CRM data
2. PROCESSING (All within EU/EEA)
Audio/Video → Speech-to-Text engine
• Automated transcription
• Speaker identification & diarisation
• Multi-language support
• Metadata extraction
3. ANALYSIS
Transcript → AI/NLP Models
• Summarisation
• Topic extraction
• Pattern recognition
• Process/checklist tracking
• Sentiment indicators
• MEDDPICC scoring
4. STORAGE
Structured database
• Original recordings
• Transcripts with timestamps
• AI-generated insights
• All linked together
5. ACCESS
Customer interface
• Natural language queries
• Department-based views
• Role-based permissions
Describe the AI analysis process:
- Audio/video recorded → Stored in EU/EEA infrastructure (Scaleway, France)
- Speech-to-text transcription → Google Cloud EMEA (Ireland), real-time processing
- Text submitted to AI models → Both proprietary and Google LLMs
- Insights generated → Each linked to source transcript via timestamps
- Presented to users → As suggestions, no autonomous decisions
- LLM session ends → No retention beyond processing
Technical components:
Infrastructure:
- Cloud hosting: Entire Nordic (Sweden) + Scaleway (France)
- LLM provider: Google Cloud EMEA Limited (Ireland)
- All infrastructure ISO 27001, SOC 2/3 certified
Security:
- End-to-end encryption (TLS 1.2/1.3 in transit, AES-256 at rest)
- Zero trust network access
- Role-based access control (RBAC)
- Multi-factor authentication (MFA)
Key technical capabilities:
- Real-time/near-real-time processing
- No LLM data retention
- Human-in-the-loop design
- Evidence-based insights (always linked to source)
- Progressive AI agents (roadmap feature)
5. Integration architecture:
- RESTful APIs
- Webhook support
- Native CRM connectors
- Calendar sync
- Email integration